Machine Learning Training
Machine Learning Training API allows you to construct, control, and train a machine learning model in Tizen devices.
The main features of Machine Learning Training API include:
- Constructing a deep neural network (DNN)
- You can construct a DNN model using a model description file or by writing code through Machine Learning Training API.
- Training with your own data
- Machine Learning Training API also allows you to train the model with your own data as a File I/O or by defining a data generator.
- Evaluating the model during training
- You can validate and test your model during the training process easily by defining the dataset.
NoteEvery example code does not handle all error use cases. The error must be handled more extensively compared to the example code written on this page.
Prerequisites
To enable your application to use Machine Learning Training API, go through the following steps:
-
To use the functions and data types of the Machine Learning Inference API, include the
<nntrainer.h>header file in your application:#include <nntrainer.h> -
To use the Machine Learning Training API, include the following features in your
tizen-manifest.xmlfile:<feature name="http://tizen.org/feature/machine_learning">true</feature> <feature name="http://tizen.org/feature/machine_learning.training">true</feature>In case of saving or loading model files from the outside of the application’s own resources, the application has to request permission by adding the following privileges to the
tizen-manifest.xmlfile:<privileges> <!-- For accessing media storage --> <privilege>http://tizen.org/privilege/mediastorage</privilege> <!-- For accessing external storage --> <privilege>http://tizen.org/privilege/externalstorage</privilege> </privileges>
Building blocks
Following are the four major components of Machine Learning Training API:
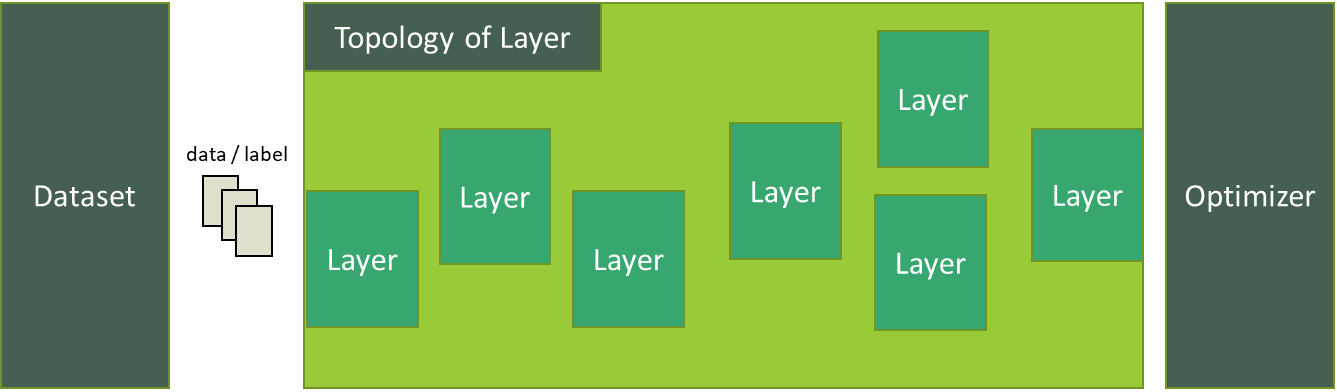
Model
Model is a wrapper component that has the topology of layers, optimizers, and datasets.
The model performs training and saves the updated parameters that can later be used for inference.
In the following figure, data represents input data or feature and label is the actual value to be tested over prediction:
NoteUntil Tizen 6.0, only sequential neural network is supported, and since Tizen 6.5, neural network with directed acyclic graph structure is also supported.
// Create model
ml_train_model_h model;
ml_train_model_construct(&model);
/* Configure model(omitted for brevity) */
// Compile model - This freezes the model. Afterwards the model cannot be modified.
ml_train_model_compile(model, "loss=cross", "batch_size=16", NULL);
// Run model
ml_train_model_run(model, "epochs=2", NULL);
// Save and load below format supported since Tizen 6.5:
ml_train_model_save(model, "model_weights.bin", ML_TRAIN_MODEL_FORMAT_BIN);
ml_train_model_save(model, "model.ini", ML_TRAIN_MODEL_FORMAT_INI);
ml_train_model_save(model, "model_and_weights.ini", ML_TRAIN_MODEL_FORMAT_INI_WITH_BIN);
// Destroy after use.
ml_train_model_destroy(model);
A number of properties can be set at ml_train_model_compile() and ml_train_model_run() phase:
| Function | Key | Value | Description |
|---|---|---|---|
ml_train_model_run() |
epochs | (integer) | Determines epochs for the model |
| | save_path | (string) | Model path to save parameters after a single epoch |
Layer
Layer is a component that does actual computation while managing internal trainable parameters. The following example shows how to create, add and get layer to the model:
// Create layer
ml_train_layer_h layer;
ml_train_layer_h get_layer;
ml_train_layer_create(&layer, ML_TRAIN_LAYER_TYPE_FC);
// Configure layer
ml_train_layer_set_property(layer, "unit=10", "activation=softmax", "bias_initializer=zeros", "name=fc100", NULL);
// After adding the layer to model, you do not need to destroy layer since ownership is transferred to the model.
ml_train_model_add_layer(model, layer);
// Get layer from the model with the given name.
// The returned layer must not be deleted as it is owned by the model.
ml_train_model_get_layer(model, "fc100", &get_layer);
There are two types of layers. One type includes commonly trainable weights and the other type does not include them. The following are the available properties for each layer type which include commonly trainable weights:
| Type | Key | Value | Default value | Description |
|---|---|---|---|---|
| (Universal properties) | Universal properties that apply to every layer | |||
| | name | (string) | An identifier for each layer | |
| | trainable | (boolean) | true | Allow weights to be trained if true |
| | input_layers | (string) | Comma-separated names of layers to be inputs of the current layer | |
| | input_shape | (string) | Comma-separated formatted string as “channel:height:width”. If there is no channel then it must be 1. The first layer of the model must have input_shape. Other can be omitted as it is calculated at compile phase. | |
| | flatten | (boolean) | Flatten shape from c:h:w to 1:1:c*h*w |
|
| | activation | (categorical) | Activation type | |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | loss | (float) | 0 | Loss |
| | weight_initializer | (categorical) | xavier_uniform | Weight initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | bias_initializer | (categorical) | zeros | Bias initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | weight_regularizer | (categorical) | Weight regularizer. Currently, only l2norm is supported | |
| | l2norm | L2 weight regularizer | ||
| | weight_regularizer_constant | (float) | 1 | Weight regularizer constant |
ML_TRAIN_LAYER_TYPE_FC |
Fully connected layer | |||
| | unit | (unsigned integer) | Number of outputs | |
ML_TRAIN_LAYER_TYPE_CONV1D (since 7.0) |
1D Convolution layer | |||
| | filters | (unsigned integer) | Number of filters | |
| | kernel_size | (unsigned integer) | Kernel size | |
| | stride | (unsigned integer) | 1 | Strides |
| | padding | (categorical) | valid | Padding type |
| | valid | No padding | ||
| | same | Preserve dimension | ||
| | (unsigned integer) | Size of padding applied uniformly to all side | ||
| | (array of unsigned integer of size 2) | Padding for left, right | ||
ML_TRAIN_LAYER_TYPE_CONV2D (since 6.5) |
2D Convolution layer | |||
| | filters | (unsigned integer) | Number of filters | |
| | kernel_size | (array of unsigned integer) | Comma-separated unsigned integers for kernel size, height, width respectively |
|
| | stride | (array of unsigned integer) | 1, 1 | Comma-separated unsigned integers for strides, height, width respectively |
| | padding | (categorical) | valid | Padding type |
| | valid | No padding | ||
| | same | Preserve height/width dimension | ||
| | (unsigned integer) | Size of padding applied uniformly to all side | ||
| | (array of unsigned integer of size 2) | Padding for height, width | ||
| | (array of unsigned integer of size 4) | Padding for top, bottom, left, right | ||
ML_TRAIN_LAYER_TYPE_EMBEDDING (since 6.5) |
Embedding layer | |||
| | in_dim | (unsigned integer) | Vocabulary size | |
| | out_dim | (unsigned integer) | Word embedding size | |
ML_TRAIN_LAYER_TYPE_RNN (since 6.5) |
RNN layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | return_sequences | (boolean) | false | Return only the last output if true, else return full output |
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
ML_TRAIN_LAYER_TYPE_RNNCELL (since 7.0) |
RNN cell layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
ML_TRAIN_LAYER_TYPE_LSTM (since 6.5) |
LSTM layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | recurrent_activation | (categorical) | sigmoid | Activation type for recurrent step |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | return_sequences | (boolean) | false | Return only the last output if true, else return full output |
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
| | max_timestep | (unsigned integer) | Maximum timestep | |
ML_TRAIN_LAYER_TYPE_LSTMCELL (since 7.0) |
LSTM cell layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | recurrent_activation | (categorical) | sigmoid | Activation type for recurrent step |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
ML_TRAIN_LAYER_TYPE_GRU (since 6.5) |
GRU layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | recurrent_activation | (categorical) | sigmoid | Activation type for recurrent step |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | return_sequences | (boolean) | false | Return only the last output if true, else return full output |
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
| | reset_after | (boolean) | true | Apply reset gate before/after the matrix |
ML_TRAIN_LAYER_TYPE_GRUCELL (since 7.0) |
GRU cell layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | reset_after | (boolean) | true | Apply reset gate before/after the matrix multiplication |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | recurrent_activation | (categorical) | sigmoid | Activation type for recurrent step |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | dropout | (float) | 0 | Dropout rate |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
ML_TRAIN_LAYER_TYPE_ZONEOUTLSTMCELL (since 7.0) |
Zoneout LSTM cell layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | hidden_state_activation | (categorical) | tanh | Activation type |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | recurrent_activation | (categorical) | sigmoid | Activation type for recurrent step |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | cell_state_zoneout_rate | (float) | 0 | Zoneout rate for cell state |
| | hidden_state_zoneout_rate | (float) | 0 | Zoneout rate for hidden state |
| | integrate_bias | (boolean) | false | Integrate bias_ih, bias_hh to bias_h |
ML_TRAIN_LAYER_TYPE_ATTENTION (since 7.0) |
Attention layer | |||
| | n/a | |||
ML_TRAIN_LAYER_TYPE_MOL_ATTENTION (since 7.0) |
MOL attention layer | |||
| | unit | (unsigned integer) | Number of output neurons | |
| | MoL_K | (unsigned integer) | Size of the three projections | |
ML_TRAIN_LAYER_TYPE_MULTI_HEAD_ATTENTION (since 7.0) |
Multi head attention layer | |||
| | num_heads | (unsigned integer) | 1 | Number of head |
| | projected_key_dim | (unsigned integer) | Projected key dim per head | |
| | projected_value_dim | (unsigned integer) | Projected value dim per head | |
| | output_shape | (unsigned integer) | Output shape of multi head | |
| | dropout_rate | (float) | 0 | Drop rate |
| | return_attention_weight | (categorical) | none | Return attention weight |
| | none | Return none | ||
| | before | Return attention weight before applying dropout | ||
| | after | Return attention weight after applying dropout | ||
| | average_attention_weight | (boolean) | true | Average attention weight |
ML_TRAIN_LAYER_TYPE_LAYER_NORMALIZATION (since 7.0) |
Layer normalization layer | |||
| | axis | (unsigned integer) | Index in the dimension | |
| | epsilon | (float) | 0.001 | Epsilon value |
| | gamma_initializer | (categorical) | none | Gamma initialization |
| | zeros | Zero initialization | ||
| | ones | One initialization | ||
| | lecun_normal | Lecun normal initialization | ||
| | lecun_uniform | Lecun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | none | No initialization | ||
| | beta_initializer | (categorical) | none | Beta initialization |
| | zeros | Zero initialization | ||
| | ones | One initialization | ||
| | lecun_normal | Lecun normal initialization | ||
| | lecun_uniform | Lecun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | none | No initialization | ||
| | weight_decay | (float) | 0 | Define how much to decay the weight |
| | bias_decay | (float) | 0 | Define how much regularize the weight |
ML_TRAIN_LAYER_TYPE_POSITIONAL_ENCODING (since 7.0) |
Positional encoding layer | |||
| | max_timestep | (unsigned integer) | Maximum timestep |
The following are the available properties for each layer type which do not include (weight_initializer, bias_initializer, weight_regularizer, weight_regularizer_constant) properties:
| Type | Key | Value | Default value | Description |
|---|---|---|---|---|
| (Universal properties) | Universal properties that apply to every layer | |||
| | name | (string) | An identifier for each layer | |
| | trainable | (boolean) | true | Allow weights to be trained if true |
| | input_layers | (string) | Comma-separated names of layers to be inputs of the current layer | |
| | input_shape | (string) | Comma-separated formatted string as “channel:height:width”. If there is no channel then it must be 1. First layer of the model must have input_shape. Other can be omitted as it is calculated at compile phase. | |
| | flatten | (boolean) | Flatten shape from c:h:w to 1:1:c*h*w |
|
| | activation | (categorical) | Activation type | |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
| | loss | (float) | 0 | Loss |
ML_TRAIN_LAYER_TYPE_INPUT |
Input layer | |||
| | normalization | (boolean) | false | Normalize input if true |
| | standardization | (boolean) | false | Standardize input if true |
ML_TRAIN_LAYER_TYPE_BN (since 6.5) |
Batch normalization layer | |||
| | epsilon | (float) | 0.001 | Small value to avoid dividing by zero |
| | moving_mean_initializer | (categorical) | zeros | Moving mean initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | moving_variance_initializer | (categorical) | ones | Moving variance initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | gamma_initializer | (categorical) | ones | Gamma initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | beta_initializer | (categorical) | zeros | Beta initializer |
| | zeros | Zero initialization | ||
| | lecun_normal | LeCun normal initialization | ||
| | lecun_uniform | LeCun uniform initialization | ||
| | xavier_normal | Xavier normal initialization | ||
| | xavier_uniform | Xavier uniform initialization | ||
| | he_normal | He normal initialization | ||
| | he_uniform | He uniform initialization | ||
| | momentum | (float) | 0.99 | Momentum for moving average in batch normalization |
ML_TRAIN_LAYER_TYPE_POOLING2D (since 6.5) |
Pooling layer | |||
| | pooling | (categorical) | Pooling type | |
| | max | Max pooling | ||
| | average | Average pooling | ||
| | global_max | Global max pooling | ||
| | global_average | Global average pooling | ||
| | pool_size | (array of unsigned integer) | Comma-separated unsigned intergers for pooling size, height, width respectively |
|
| | stride | (array of unsigned integer) | 1, 1 | Comma-separated unsigned intergers for stride, height, width respectively |
| | padding | (categorical) | valid | Padding type |
| | valid | No padding | ||
| | same | Preserve height/width dimension | ||
| | (unsigned integer) | Size of padding applied uniformly to all side | ||
| | (array of unsigned integer of size 2) | Padding for height, width | ||
| | (array of unsigned integer of size 4) | Padding for top, bottom, left, right | ||
ML_TRAIN_LAYER_TYPE_FLATTEN (since 6.5) |
Flatten layer | |||
ML_TRAIN_LAYER_TYPE_ACTIVATION (since 6.5) |
Activation layer | |||
| | activation | (categorical) | Activation type | |
| | tanh | Hyperbolic tangent | ||
| | sigmoid | Sigmoid function | ||
| | relu | Relu function | ||
| | softmax | Softmax function | ||
ML_TRAIN_LAYER_TYPE_ADDITION (since 6.5) |
Addition layer | |||
ML_TRAIN_LAYER_TYPE_CONCAT (since 6.5) |
Concat layer | |||
ML_TRAIN_LAYER_TYPE_MULTIOUT (since 6.5) |
Multiout layer | |||
ML_TRAIN_LAYER_TYPE_SPLIT (since 6.5) |
Split layer | |||
| | split_dimension | (unsigned integer) | Which dimension to split. Split batch dimension is not allowed | |
ML_TRAIN_LAYER_TYPE_PERMUTE (since 6.5) |
Permute layer | |||
ML_TRAIN_LAYER_TYPE_DROPOUT (since 6.5) |
Dropout layer | |||
| | dropout | (float) | 0 | Dropout rate |
ML_TRAIN_LAYER_TYPE_BACKBONE_NNSTREAMER (since 6.5) |
NNStreamer layer | |||
| | model_path | (string) | NNStreamer model path | |
ML_TRAIN_LAYER_TYPE_CENTROID_KNN (since 6.5) |
Centroid KNN layer | |||
| | num_class | (unsigned integer) | Number of class | |
ML_TRAIN_LAYER_TYPE_PREPROCESS_FLIP (since 6.5) |
Preprocess flip layer | |||
| | flip_direction | (categorical) | Flip direction | |
| | horizontal | Horizontal direction | ||
| | vertical | Vertical direction | ||
| | horizontal_and_vertical | horizontal_and_vertical | Horizontal and vertical direction | |
ML_TRAIN_LAYER_TYPE_PREPROCESS_TRANSLATE (since 6.5) |
Preprocess translate layer | |||
| | random_translate | (float) | Translate factor value | |
ML_TRAIN_LAYER_TYPE_PREPROCESS_L2NORM (since 6.5) |
Preprocess l2norm layer | |||
ML_TRAIN_LAYER_TYPE_LOSS_MSE (since 6.5) |
MSE loss layer | |||
ML_TRAIN_LAYER_TYPE_LOSS_CROSS_ENTROPY_SIGMOID (since 6.5) |
Cross entropy with sigmoid loss layer | |||
ML_TRAIN_LAYER_TYPE_LOSS_CROSS_ENTROPY_SOFTMAX (since 6.5) |
Cross entropy with softmax loss layer | |||
ML_TRAIN_LAYER_TYPE_IDENTITY (since 8.0) |
Identity layer |
Optimizer
Optimizer determines how to update model parameters according to loss from prediction. Currently, Stochastic Gradient Descent optimizer and Adam optimizer are supported:
// Create an optimizer
ml_train_optimizer_h optimizer;
ml_train_optimizer_create(&optimizer, ML_TRAIN_OPTIMIZER_TYPE_SGD);
// Configure an optimizer
ml_train_optimizer_set_property(optimizer, "learning_rate=0.001", NULL);
// Set optimizer to the model
// No need to destroy optimizer after setting optimizer since the ownership is transferred to the model.
ml_train_model_set_optimizer(model, optimizer);
Following are the available properties for each optimizer type:
| Type | Key | value | Description |
|---|---|---|---|
| (Universal properties) | Universal properties that apply to every layer | ||
| | learning_rate | (float) | Initial learning rate for the optimizer |
ML_TRAIN_OPTIMIZER_TYPE_SGD |
Stochastic Gradient Descent optimizer | ||
ML_TRAIN_OPTIMIZER_TYPE_ADAM |
Adam optimizer | ||
| | beta1 | (float) | Beta1 coefficient for Adam |
| | beta2 | (float) | Beta2 coefficient for Adam |
| | epsilon | (float) | Epsilon coefficient for Adam |
Learning rate scheduler
Learning rate scheduler determines how to adjust the learning rate. Currently constant, exponential, and step type is supported:
// Create learning rate scheduler
ml_train_lr_scheduler_h scheduler;
ml_train_lr_scheduler_create(&scheduler, ML_TRAIN_LR_SCHEDULER_TYPE_CONSTANT);
// Configure learning rate scheduler
ml_train_lr_scheduler_set_property(scheduler, "learning_rate=0.001", NULL);
// Set learning rate scheduler to optimizer
ml_train_optimizer_h optimizer;
ml_train_optimizer_set_lr_scheduler(optimizer, scheduler);
// Set optimizer to the model
ml_train_model_set_optimizer(model, optimizer);
Following are the available properties for each learning rate scheduler type:
| Type | Key | Value | Description |
|---|---|---|---|
ML_TRAIN_LR_SCHEDULER_TYPE_CONSTANT |
|||
| | LearningRate | (float) | LearningRate |
ML_TRAIN_LR_SCHEDULER_TYPE_EXPONENTIAL |
|||
| | LearningRate | (float) | LearningRate |
| | DecayRate | (float) | Decay rate |
| | DecaySteps | (float) | Decay steps |
ML_TRAIN_LR_SCHEDULER_TYPE_STEP |
|||
| | LearningRate | (array of float) | LearningRate |
| | Iteration | (array of unsigned integer) | Iteration |
Dataset
Dataset is in charge of feeding data into the model. The dataset can either be created from a callback function or created from a file. For more information, see configure the model section.
The following code is an example of handling dataset:
// Create dataset
ml_train_dataset_h dataset;
ml_train_dataset_construct(&dataset);
ml_train_dataset_add_file(&dataset, train_path, ML_TRAIN_DATASET_MODE_TRAIN);
ml_train_dataset_add_generator(&dataset, get_sample, (void *)val_user_data, ML_TRAIN_DATASET_MODE_VALID);
ml_train_dataset_add_generator(&dataset, get_sample, (void *)test_user_data, ML_TRAIN_DATASET_MODE_TEST);
// configure dataset
ml_train_dataset_set_property_for_mode(dataset, ML_TRAIN_DATASET_MODE_TRAIN, "buffer_size=100", NULL);
// after setting a dataset to model,
// you do not need to destroy dataset since ownership is transferred to the model.
ml_train_model_set_dataset(model, dataset);
Construct a model
A model can be constructed with ml_train_model_construct().
If you have a file that describes the model, the file can be used to construct initially with ml_train_model_construct_with_file().
Even if the model is constructed from a file, switching, modifying, or setting a component is possible until you compile with ml_train_model_compile().
Construct a model from a description file
As of now, only INI formatted files *.ini are supported to construct a model from a file.
Create a model from INI formatted file
Special sections [Model], [Optimizers], [train_set], [valid_set], [test_set], [LearningRateScheduler] are respectively referring to model, optimizer and data provider objects.
Rest of INI sections map to a layer. Keys and values from each section set properties of the layer.
All keys and values are treated as case-insensitive.
Following is an example of the *.ini file:
[Model] # Special section that describes model itself
Type = NeuralNetwork # Model type : only NeuralNetwork is supported as of now
batch_size = 9
#### Model run related properties
Epochs = 20 # Epochs
[Optimizer]
Type = adam # Optimizer : Adaptive Moment Estimation(adam)
beta1 = 0.9 # beta 1 for adam
beta2 = 0.9999 # beta 2 for adam
epsilon = 1e-7 # epsilon for adam
[LearningRateScheduler]
type = constant
Learning_rate = 1e-4
[train_set]
Type = file
BufferSize = 9
path = "trainingSet.dat"
[valid_set]
Type = file
path = "valSet.dat"
# Add [test_set] section if applicable
# Layer Sections, each section name refers to name of the layer
[inputlayer]
Type = input
Input_Shape = 1:1:62720 # Input dimension in channel:height:width
Normalization = true
[outputlayer]
Type = fully_connected
Unit = 2 # Width of output dimension
bias_initializer = zeros
weight_initializer = xavier_uniform
Activation = sigmoid # activation : sigmoid, softmax
weight_regularizer = l2norm
weight_regularizer_constant = 0.005
input_layers = inputlayer
[loss]
Type = cross # Define loss as a layer
The following restrictions must be adhered to:
- Model file must have a
[Model]section. - Model file must have at least one layer.
- Valid keys must have valid properties. The invalid keys in each section result in an error.
NoteAll paths inside the INI file are relative to the INI file path unless the absolute path is stated. Consider setting
save_path,train_set,valid_set, andtest_setfrom the code rather than describing inside the model file to avoid this behavior.
Following example constructs model from INI file:
char *res_path = app_get_resource_path();
char model_path[1024];
ml_train_model_h model;
snprintf(model_path, sizeof(model_path), "%s/model.ini", res_path);
free(res_path);
status = ml_train_model_construct_with_conf(model_path, &model);
if(status != ML_ERROR_NONE) {
// handle error
}
Construct a model on code
An empty model can be constructed with ml_train_model_construct().
Configure the model
After constructing a model, the model can be configured.
NoteExample code written here reproduces the model description from Create Model from INI Formatted File except that following is different:
- Relative path is changed to dynamic app resource and data path.
- Model related properties that can only be set at compile or run phase.
- Demonstration about
ml_train_dataset_add_generator(), which cannot be covered in the description file.
First, an empty model needs to be created:
ml_train_model_h model;
ml_train_model_construct(&model);
Add a layer
ml_train_model_add_layer() appends a layer to the end of the graph in the model:
int status = ML_ERROR_NONE;
ml_train_layer_h layers[2];
// create and add input layer
status = ml_train_layer_create(&layers[0], ML_TRAIN_LAYER_TYPE_INPUT);
if(status != ML_ERROR_NONE) {
// handle error
}
status = ml_train_layer_set_property(layers[0], "name=inputlayer",
"input_shape=1:1:62720",
"normalization=true", NULL);
if(status != ML_ERROR_NONE) {
//handle error
}
status = ml_train_model_add_layer(model, layers[0]);
// create and add fully connected layer
status = ml_train_layer_create(&layers[1], ML_TRAIN_LAYER_TYPE_FC);
status = ml_train_layer_set_property(layers[1], "name=outputlayer",
"unit=2",
"bias_initializer=zeros",
"weight_initializer=xavier_uniform",
"activation=sigmoid", NULL);
status = ml_train_model_add_layer(model, layers[1]);
Get a layer
ml_train_model_get_layer() gets a layer from the model with the given name:
int status = ML_ERROR_NONE;
ml_train_model_h model;
ml_train_layer_h add_layer;
ml_train_layer_h get_layer;
// constructs the neural network model
status = ml_train_model_construct(&model);
if (status != ML_ERROR_NONE) {
// handle error
}
// creates and add a neural network layer
status = ml_train_layer_create(&add_layer, ML_TRAIN_LAYER_TYPE_INPUT);
if (status != ML_ERROR_NONE) {
// handle error
}
// set a name for the layer
status = ml_train_layer_set_property(add_layer, "name=inputlayer", NULL);
if (status != ML_ERROR_NONE) {
// handle error
}
// adds layer in neural network model
status = ml_train_model_add_layer(model, add_layer);
if (status != ML_ERROR_NONE) {
// handle error
}
// gets neural network layer from the model with the given name
status = ml_train_model_get_layer(model, "inputlayer", &get_layer);
// get_layer owned by model, Do not delet it
if (status != ML_ERROR_NONE) {
// handle error
}
Set an optimizer
Creating and setting optimizer to a model can be done in the same manner as layer:
status = ml_train_optimizer_create(&optimizer, ML_TRAIN_OPTIMIZER_TYPE_ADAM);
status = ml_train_optimizer_set_property(optimizer, "beta1=0.002",
"beta2=0.001",
"epsilon=1e-7", NULL);
status = ml_train_model_set_optimizer(model, optimizer);
Set a learning rate scheduler
Creating and setting LearningRateScheduler to a optimizer can be done in the same manner as optimizer:
status = ml_train_lr_scheduler_create(&scheduler, ML_TRAIN_LR_SCHEDULER_TYPE_CONSTANT);
status = ml_train_lr_scheduler_set_property(scheduler, "learning_rate=0.001", NULL);
status = ml_train_optimizer_set_lr_scheduler(optimizer, scheduler);
Set a dataset
There are two ways to create a dataset. One is from a file, and the other one is from a callback. In either case, you need to provide streams of tensor data and arrays of values representing the label, usually one-hot-encoded.
Sample, batch and epoch
This section explains the following three concepts: sample, batch and epoch.
Let’s assume a given model requires three inputs and two labels. This has been reflected in the examples below:
-
Sample
A sample denotes a single pair of inputs/labels. The example can be as follows:
[input_1][input_2][input_3][label_1][label_2] -
Batch
A batch is a bundle of samples which is fed to a single iteration. If a batch is of size 5, the batch layout, where
/*denotes nth sample will be as follows:[[input_1/1][input_1/2][input_1/3][input_1/4][input_1/5]], [[input_2/1][input_2/2][input_2/3][input_2/4][input_2/5]], [[input_3/1][input_3/2][input_3/3][input_3/4][input_3/5]], [[label_1/1][label_1/2][label_1/3][label_1/4][label_1/5]], [[label_2/1][label_2/2][label_2/3][label_2/4][label_2/5]], -
Epoch
An epoch refers to a full, exhaustive visit to a dataset.
So, if you consider Cifar-100 dataset when using the full training set, a single training epoch will contain 50,000 samples. If batch size is 100, it will be of 500 batches (or iterations).
Construct a dataset on code
An empty dataset handle can be constructed with ml_train_model_create().
The handle abstracts data, providing logics with three dataset usage point: ML_TRAIN_DATASET_MODE_TRAIN, ML_TRAIN_DATASET_MODE_VALID, ML_TRAIN_DATASET_MODE_TEST
A data provider added with ML_TRAIN_DATASET_MODE_TRAIN, ML_TRAIN_DATASET_MODE_VALID, ML_TRAIN_DATASET_MODE_TEST will be used when training, validating, training respectively.
Consider setting property with ml_train_model_set_property_for_mode() when data provider needs certain properties.
Set a dataset from file
To create a dataset from files, each file must contain an array of samples.
A single sample consists of an array of raw float array for input and another array or raw float array for labels that contains the same size as model output:
# If a model requires two inputs and a single label for a sample, a single sample would contain...
[[float array for input1][input 2][float array for label1]],
...,
[[float array for input1][input 2][float array for label1]]
As an example, again, consider Cifar-100 dataset. In Cifar-100 data, it contains an image of size 3 * 32 * 32 and a coarse label of 20 classes and a fine label of 100 classes.
If your model requires an image and two labels (coarse, fine) both one-hot encoded for a sample, the file layout would be:
[[3072 pixels][20 floats for coarse label][100 floats for fine label]],
...
...
[[3072 pixels][20 floats for coarse label][100 floats for fine label]]
After preparing the file, create dataset as follows:
int status = ML_ERROR_NONE;
ml_train_dataset_h dataset;
ml_train_dataset_create(&dataset)
char *res_path = app_get_resource_path();
char train_path[1024];
snprintf(train_path, sizeof(train_path), "%s/training.dat", res_path);
free(res_path);
// a file data provider to be used for training
status = ml_train_dataset_add_file(&dataset, train_path, ML_TRAIN_DATASET_MODE_TRAIN);
if(status != ML_ERROR_NONE) {
// handle error
}
status = ml_train_dataset_set_property_for_mode(dataset, ML_TRAIN_DATASET_MODE_TRAIN, "buffer_size=9", NULL);
status = ml_train_model_set_dataset(model, dataset);
The property buffer_size defines the maximum amount of batches to be queued while training. When it is not given, it is set to 1.
Set a dataset from a generator
Creating a data provider from a generator function and setting it to dataset is also possible.
-
Prepare a callback function:
/** * @brief fill a single sample * @see ml_train_datagen_cb for details * @param[in/out] array of allocated input buffers ready to be filled * @param[in/out] array of allocated label buffers ready to be filled * @param[in/out] last if the data is finished * @param[in] user_data private data for the callback * @retval status for handling error while training, returning non-zero will cause to abort data fetching. */ int get_train_data(float **inputs, float **labels, bool *last, void *user_data) { /* code that fills data, label and last */ return ML_ERROR_NONE; } -
Create a dataset from the callback function:
int status = ML_ERROR_NONE; ml_train_dataset_h dataset; ml_train_dataset_create(&dataset) /// assuming user_data is retrived from `get_user_data()` custom_type * user_data = get_user_data(); // a generator based provider to be used for training status = ml_train_dataset_add_generator(&dataset, get_train_data, (void *)user_data, ML_TRAIN_DATASET_MODE_TRAIN); if(status != ML_ERROR_NONE) { // handle error } status = ml_train_dataset_set_property_for_mode(dataset, "buffer_size=9", NULL); status = ml_train_model_set_dataset(model, dataset);
The property buffer_size defines the maximum amount of batches to be queued while training. When it is not given, it is set to 1.
Compile the model
Compiling a model finalizes the model with loss. Once compiled, any modification to the properties of the model is restricted. Adding layers or changing the optimizer or dataset of the model is not permitted either:
int status = ML_ERROR_NONE;
status = ml_train_model_compile(model, "loss=cross", NULL);
Train the model
Now, the model is ready to train. Train model as follows:
int status = ML_ERROR_NONE;
status = ml_train_model_run(model, "batch_size=9", "epochs=20", NULL);
Destroy the model
After training, the model must be destroyed with ml_train_model_destroy().
ml_train_model_add_layer(), ml_train_set_optimizer(), and ml_train_set_dataset() transfers ownership to the model.
layers, optimizers and dataset that belongs to the model are also deleted.
Use the trained model for inference
NoteThis feature is supported since Tizen 6.5 only.
The trained model can be used for inference with Machine Learning Inference API.
Ensure that the INI file contains the correct weight file in save_path in [Model] section.
The valid INI file can be made from ml_train_model_h with ml_train_model_save() if you have constructed the model with the provided API.
For example, you can use the trained model with a single API as follows:
#include <nnstreamer-single.h>
ml_single_h single;
ml_tensors_info_h in_info, out_info;
...
ml_single_open (&single, "model_file.ini", in_info, out_info, ML_NNFW_TYPE_NNTR_INF, ML_NNFW_HW_ANY);
You can use the trained model with pipeline API as follows:
ml_pipeline_h pipe;
/* framework is 'nntrainer'*/
const char pipeline[] = "appsrc ! other/tensor,dimension=(string)2:1:1:1,type=(string) int8,framerate=(fraction)0/1 ! tensor_filter framework=nntrainer model=model.ini ! tensor_sink";
status = ml_pipeline_construct (pipeline, NULL, NULL, &pipe);
Related information
- Dependencies
- Since Tizen 6.0
- API References